Amazon SageMaker 紹介 - 組み込みアルゴリズムで機械学習を試す

Amazon SageMaker を紹介する勉強会を開催しました。「雲勉@オンライン【勉強会】Amazon SageMaker 入門 〜組み込みアルゴリズムで機械学習を試してみよう〜【開発エンジニア向け】」
プレゼンテーションの内容を紹介し、 SageMaker を知るきっかけになれば幸いです。この投稿のサンプルは、 GitHub リポジトリから取得できます。

前提条件
参加者は以下が期待されます:
- SageMaker に興味を持っていること
- 機械学習と AWS の基礎知識
この投稿の目標:
- 機械学習と SageMaker エコシステムの概要把握
- SageMaker 組み込みアルゴリズムを使用した教師あり機械学習のデモ
機械学習概要
教師あり学習
教師あり学習は、分類および回帰のタスクによく使用されます。 訓練データとラベル付けされたデータの両方が必要です。データのラベリングが負担になることがあります。
教師なし学習
教師なし学習は、クラスタリングや次元削減などのタスクによく使用されます。 訓練データが必要です。ほとんどの場合、この手法は推論結果に対する明確な説明を提供しません。
強化学習
強化学習は純粋な統計解析手法ではなく、心理学的なアプローチを含みます。 訓練データと報酬が必要です。推論結果に基づいて報酬(重み)が割り当てられ、アルゴリズムはより大きな報酬につながる行動を学習します。
深層学習
深層学習(以降、ディープラーニング)は、近年注目を集めている機械学習の手法です。高い精度を達成するために複数のニューラルネットワークを使用し、人間の予測結果を上回ることがあります。
ディープラーニングでは、自動での特徴量選択が可能になりつつあります。 正確な予測を生成する一方で、ディープラーニングは推論結果に対する明確な説明を提供しません。ディープラーニングモデルの訓練には、多くの計算リソースが必要です。
ニューラルネットワーク
ニューラルネットワークの複雑さを示す指標の一つは、重みの合計です。以下の例では、複雑さは 24 です。
4 (特徴量) * 3 (隠し層1) = 12
3 (隠し層1) * 3 (隠し層2) = 9
3 (隠し層2) * 1 (出力) = 3
12 + 9 + 3 = 24

| Value | Description |
|---|---|
| y | 結果 |
| x | 特徴量 |
| w | 重み |
| h1, h2 | 隠し層 |
| h1[0], h1[1], … h2[2] | 隠れユニット |
特徴量
行はサンプルまたはデータポイントと呼ばれます。列は特徴と呼ばれます。特徴量エンジニアリングは、推論の精度を向上させるために重要です。これには、特徴量の抽出、変換、またはスケーリングが含まれます。前処理は、生データが含む不要な情報を取り除きます。特徴量エンジニアリングには、 One-hot エンコーディング、リスケーリング、主成分分析 (PCA) などのさまざまな方法があります。
モデル評価
手法 (k-分割交差検証)
以下の図は、k-分割交差検証を説明しています。緑は訓練データで、青はテストデータです。

各セットは異なる組み合わせの訓練データとテストデータを持ち、そのセットの精度を計算します。すべてのセットの平均精度はモデルの平均と見なすことができます。各セット間で精度が大きく変動する場合、モデルはうまく汎化できていない可能性があり、特定のデータセットに過剰適合する原因になっているかもしれません。
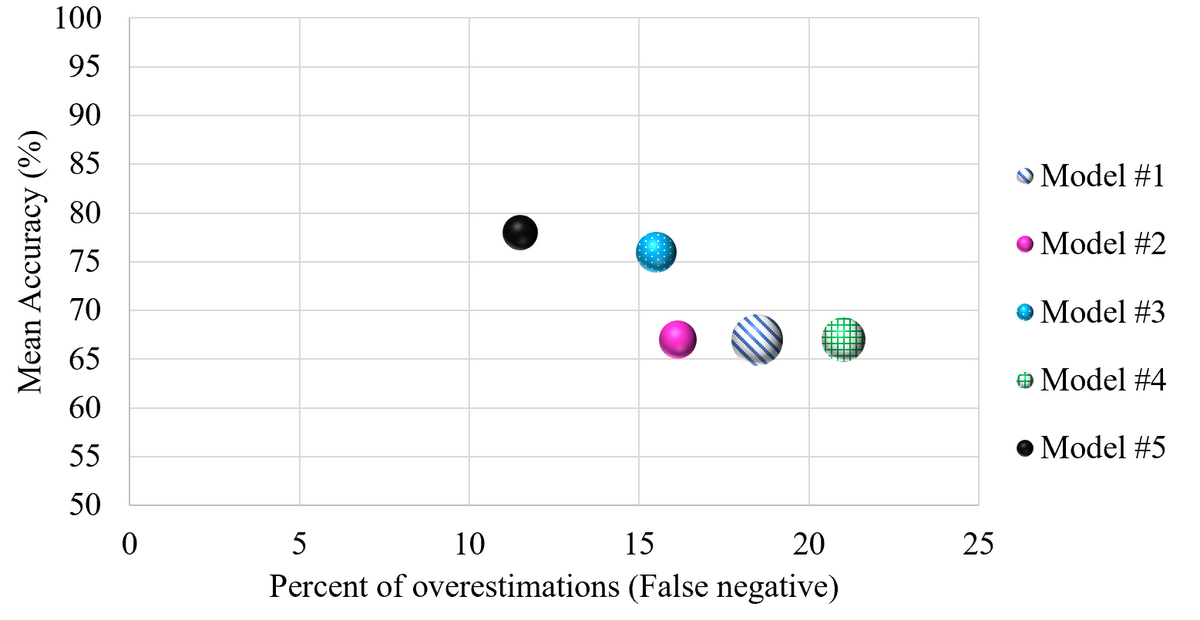
指標 (混同行列)
次の表は二値分類の例です。
| Prediction | |||
|---|---|---|---|
| Positive | Negative | ||
| Result | Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) | |
以下は各指標の説明です。
| Name | Expression | Description | Problem |
|---|---|---|---|
| 精度 (Accuracy) | (TP + TN) / (TP + TN + FP + FN) | 正しく推論できた割合 | モデルが99個の偽を含む100のサンプルに対して、全てを偽と予測する場合、精度が99%になる。 |
| 適合率 (Precision) | TP / (TP + FP) | 陽性を正しく推論できた割合 | 偽陰性が重要な場合、例えばがんの診断のような場合、適合率だけを使用することは最適ではありません。 |
| 再現率 (Recall) | TP / (TP + FN) | 真陽性を推論できた割合 | 偽陽性が重要な場合、例えば徹底的ながん検査が非常に高価な場合、再現率だけを使用することは最適ではありません。 すべてのサンプルが陽性と予測される場合、再現率は100%になります。 |
| F値 | 2 * (Precision * Recall / (Precision + Recall)) | 適合率と再現率の調和平均 | すべてのサンプルが真陰性の場合、ゼロ除算によりエラーが発生します。 |
機械学習ワークフロー例
一般的なワークフローには、「サンプルデータの生成」、「モデルの訓練」、「モデルのデプロイ」が含まれます。

学習材料
- Introduction to Machine Learning with Python
- 総務省 ICTスキル総合習得プログラム コース3(データ分析) 3-5 人工知能と機械学習
- Amazon Machine Learning – Machine Learning Concepts
SageMaker 入門
SageMaker は、機械学習のためのマネージドサービスです。 AWS は機械学習ワークフローに関連する多くのサービスを提供しており、 SageMaker エコシステムは急速に発展しています。 SageMaker は、2021年12月時点で17の組み込みアルゴリズムを提供しています。 SageMaker 外で訓練されたモデルは、 AWS が提供するコンテナ (Bring Your Own Model) で利用できます。 TensorFlow や PyTorch などの主要なフレームワークもサポートされています。
ワークフローとエコシステム
以下の図は、機械学習ワークフローに関連する AWS サービスです。各サービスの詳細については、この投稿の最後をご参照ください。


推論エンドポイント
いくつかのエンドポイント種別があります。
- SageMaker Hosting Services は、常時稼働の EC2 のようなエンドポイントです。
- SageMaker Serverless Endpoints (Preview) は、コールドスタートを許容できる場合、低コストで利用可能なエンドポイントです。
- Asynchronous Inference は、推論リクエストが無い場合にオートスケールでインスタンス数をゼロにする機能を提供しています。
SageMaker Studio セットアップ
以下の選択肢から SageMaker の環境を選ぶことができます。この投稿では SageMaker Studio を使用しています。

- SageMaker Studio / RStudio on SageMaker
- 機械学習のための統合開発環境 (IDE)
- 学習目的であれば、 SageMaker JumpStart も利用できます。
- SageMaker Notebook Instances
- Jupyter Notebook のインスタンス
- 少数のデータサイエンティストが一時的に SageMaker を使用する必要がある場合に便利です。
- ローカル環境 + AWS SDK + SageMaker SDK
- 少数の開発者が一時的に SageMaker を使用する必要がある場合に便利です。
- SageMaker Studio Lab
- AWS アカウントなしで SageMaker Studio の一部機能を無料で試すことができます。
Onboard to SageMaker Domain
SageMaker Studio を使用するには、オンボーディングプロセスを完了する必要があります。
Quick Setup を選択してください。本番環境のためにドメインを作成する場合は、 Custom Setup がお勧めです。

任意の VPC を選択してください。

自動作成されたユーザーのメニューから SageMaker Studio を起動してください。

SageMaker Studio が起動します。

AWS 構成
Quick Setup

Custom Setup
Custom Setup を使用すると、 VPC エンドポイントでネットワークトラフィックを AWS 内部ネットワークに閉じることができます。

組み込みアルゴリズムを試してみる
この投稿では、 SageMaker の組み込みアルゴリズム k-NN (k-Nearest Neighbor) を、有名な Iris データセットで使用しています。
最初に、 SageMaker Studio の中央にある Notebook ボタンをクリックしてください。

データセット準備
以下の内容を持つセルを作成し、 <YOUR_S3_BUCKET> と <YOUR_SAGEMAKER_ROLE> に実際の値を指定してください。
%env S3_DATASET_BUCKET=<YOUR_S3_BUCKET>
%env S3_DATASET_TRAIN=knn/input/iris_train.csv
%env S3_DATASET_TEST=knn/input/iris_test.csv
%env S3_TRAIN_OUTPUT=knn/output
%env SAGEMAKER_ROLE=<YOUR_SAGEMAKER_ROLE>
以下の内容を持つセルを作成してください。 Python3 Data Science instance には、初めからこれらのパッケージがインストールされています。
import os
import random
import string
import boto3
import matplotlib.pyplot as plt
import pandas as pd
import sagemaker
from IPython.display import display
from sagemaker import image_uris
from sagemaker.deserializers import JSONDeserializer
from sagemaker.estimator import Estimator, Predictor
from sagemaker.inputs import TrainingInput
from sagemaker.serializers import CSVSerializer
from sklearn.model_selection import train_test_split
ノートブック全体で使用される以下の定数と変数を定義してください。
# Define constants
CSV_PATH = './tmp/iris.csv'
S3_DATASET_BUCKET = os.getenv('S3_DATASET_BUCKET')
S3_DATASET_TRAIN = os.getenv('S3_DATASET_TRAIN')
S3_DATASET_TEST = os.getenv('S3_DATASET_TEST')
S3_TRAIN_OUTPUT = os.getenv('S3_TRAIN_OUTPUT')
SAGEMAKER_ROLE = os.getenv('SAGEMAKER_ROLE')
ESTIMATOR_INSTANCE_COUNT = 1
ESTIMATOR_INSTANCE_TYPE = 'ml.m5.large'
PREDICTOR_INSTANCE_TYPE = 'ml.t2.medium'
PREDICTOR_ENDPOINT_NAME = f'sagemaker-knn-{PREDICTOR_INSTANCE_TYPE}'.replace('.', '-')
# Define variables
bucket = boto3.resource('s3').Bucket(S3_DATASET_BUCKET)
train_df = None
test_df = None
train_object_path = None
test_object_path = None
knn = None
predictor = None
AWS 公式の amazon-sagemaker-examples リポジトリから Iris データセットをダウンロードしてください。 Iris データセットに関する詳細は、公式ページをご参照ください。
# Download a sample csv
!mkdir -p tmp
!curl -o "$(pwd)/tmp/iris.csv" -L https://raw.githubusercontent.com/aws/amazon-sagemaker-examples/master/hyperparameter_tuning/r_bring_your_own/iris.csv
ダウンロードした後、以下のコードで CSV を読み込んでください。 SageMaker は CSV の最初の列をターゲットラベルとして扱いますので、 Species を最初の列に移動する必要があります。ターゲットラベルは int に変換する必要があります。
def load_csv(path: str) -> pd.DataFrame:
df = pd.read_csv(path)
# Move the last label column to the first
# See https://docs.aws.amazon.com/sagemaker/latest/dg/cdf-training.html#cdf-csv-format
df = df[['Species', 'Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width']]
# Convert target string to int
df['Species'] = df['Species'].map({'setosa': 0, 'versicolor': 1, 'virginica': 2})
return df
以下のコードを使用して、散布図を作成できます。
def plot(df: pd.DataFrame) -> None:
pd.plotting.scatter_matrix(df, figsize=(15, 15), c=df['Species'])
plt.show()

X軸は左から右に向かって、 Species, Sepal.Length, Sepal.Width, Petal.Length, Petal.Width を意味します。 Y軸は下から上に向かって、 Petal.Width, Petal.Length, Sepal.Width, Sepal.Length, Species を意味します。プロットを読むと、データポイントが明確に分類されているため、特徴量から種類が予測できそうです。
次のコードを使用して、変換された CSV ファイルを S3 バケットにアップロードしてください。
def upload_csv_to_s3(df: pd.DataFrame, object_path: str) -> str:
filename = ''.join([random.choice(string.digits + string.ascii_lowercase) for i in range(10)])
path = os.path.abspath(os.path.join('./tmp', filename))
df.to_csv(path, header=False, index=False)
# Change content-type because the default is binary/octet-stream
bucket.upload_file(path, object_path, ExtraArgs={'ContentType': 'text/csv'})
return f's3://{bucket.name}/{object_path}'
最後に、上記の手順を以下のコードで実行してください。
if __name__ == '__main__':
# Prepare data
df = load_csv(CSV_PATH)
display(df)
plot(df)
train_df, test_df = train_test_split(df, shuffle=True, random_state=0) # type: (pd.DataFrame, pd.DataFrame)
train_object_path = upload_csv_to_s3(train_df, S3_DATASET_TRAIN)
test_object_path = upload_csv_to_s3(test_df, S3_DATASET_TEST)
訓練
以下のコードを使用して、 Estimator を設定してください。
image_uri は、 AWS が提供する k-NN の ECR コンテナ URI です。
def get_estimator(**hyperparams) -> Estimator:
estimator = Estimator(
image_uri=image_uris.retrieve('knn', boto3.Session().region_name), # AWS provided container in ECR,
role=SAGEMAKER_ROLE,
instance_count=ESTIMATOR_INSTANCE_COUNT,
instance_type=ESTIMATOR_INSTANCE_TYPE,
input_mode='Pipe',
output_path=f's3://{S3_DATASET_BUCKET}/{S3_TRAIN_OUTPUT}',
sagemaker_session=sagemaker.Session(),
)
hyperparams.update({'predictor_type': 'classifier'})
estimator.set_hyperparameters(**hyperparams)
return estimator
以下のコードを使用して訓練を開始できます。
def train(estimator: Estimator, train_object_path: str, test_object_path: str) -> None:
# Specify content-type because the default is application/x-recordio-protobuf
train_input = TrainingInput(train_object_path, content_type='text/csv', input_mode='Pipe')
test_input = TrainingInput(test_object_path, content_type='text/csv', input_mode='Pipe')
estimator.fit({'train': train_input, 'test': test_input})
if __name__ == '__main__':
knn = get_estimator(k=1, sample_size=1000)
train(knn, train_object_path, test_object_path)
組み込みアルゴリズムのチャネル名は train に固定されています。訓練ジョブに test チャネルが設定されている場合、 ML モデルがテストされます。
TrainingInput の input_mode 引数に Pipe を指定することで、 Pipe モードを使用できます。これにより、データは直接 S3 バケットから SageMaker インスタンスにストリーミングされます。
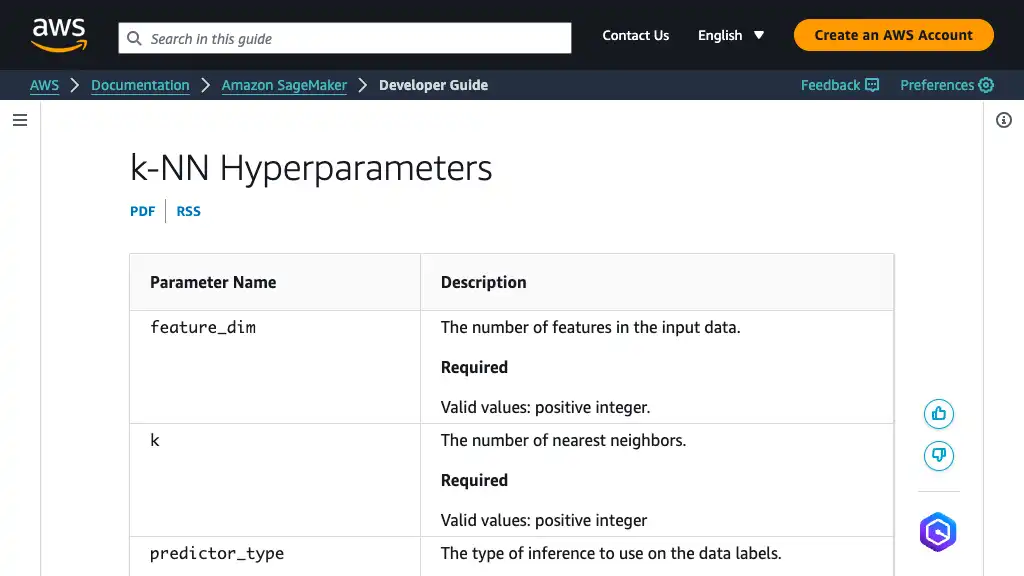
k-NN のハイパーパラメータに関する情報は、公式ドキュメントをご参照ください。
実行後、以下のような訓練ログが表示されます。
2022-01-08 13:38:34 Starting - Starting the training job...
2022-01-08 13:38:57 Starting - Launching requested ML instancesProfilerReport-1641649113: InProgress
......
[01/08/2022 13:43:00 INFO 140667182901056] #test_score (algo-1) : ('accuracy', 0.9736842105263158)
[01/08/2022 13:43:00 INFO 140667182901056] #test_score (algo-1) : ('macro_f_1.000', 0.97170347)
推論
以下のコードを使用して、推論エンドポイントをデプロイしてください。 serializer および deserializer は、想定する入力および出力の形式を意味します。
def deploy(estimator: Estimator) -> Predictor:
return estimator.deploy(
initial_instance_count=1,
instance_type=PREDICTOR_INSTANCE_TYPE,
serializer=CSVSerializer(),
deserializer=JSONDeserializer(),
endpoint_name=PREDICTOR_ENDPOINT_NAME
)
推論結果をテーブルで表示できます。
def validate(predictor: Predictor, test_df: pd.DataFrame) -> pd.DataFrame:
rows = []
for i, data in test_df.iterrows():
predict = predictor.predict(
pd.DataFrame([data.drop('Species')]).to_csv(header=False, index=False),
initial_args={'ContentType': 'text/csv'}
)
predicted_label = predict['predictions'][0]['predicted_label']
row = data.tolist()
row.append(predicted_label)
row.append(data['Species'] == predicted_label)
rows.extend([row])
return pd.DataFrame(rows, columns=('Species', 'Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width', 'Prediction', 'Result'))
Prediction, Result 列を持つ CSV データが、テーブルとして表示されます。

以下のコードで推論を実行してください。
if __name__ == '__main__':
predictor = deploy(knn)
predictions = validate(predictor, test_df)
display(predictions)
リソース削除
以下のコードを使用してリソースを削除してください。リアルタイムの推論エンドポイントは削除しない限り、追加のコストが発生します。
def delete_model(predictor: Predictor) -> None:
try:
predictor.delete_model()
print(f'Deleted a model')
except BaseException as e:
print(e)
def delete_endpoint(predictor: Predictor) -> None:
try:
predictor.delete_endpoint(delete_endpoint_config=True)
print(f'Deleted {predictor.endpoint_name}')
except BaseException as e:
print(e)
if __name__ == '__main__':
delete_model(predictor)
delete_endpoint(predictor)
SageMaker Ecosystem 参照リンク
IDE
CI/CD
Jupyter Notebook
Preprocessing
- SageMaker Data Wrangler
- SageMaker Processing
- SageMaker Ground Truth
- SageMaker Ground Truth Plus
- SageMaker Feature Store
